


2025년 5월, 구글은 I/O 발표를 통해 자사의 뛰어난 AI 기술이 앞으로 모든 제품과 서비스에 스며들어 사용자 경험을 혁신할 미래를 발표했습니다. 구글 CEO 순다르 피차이는 기존연설에서 “이론이 현실이 되다”라는 메시지를 전하며, 뛰어난 성능의 제미나이 모델과 이를 뒷받침하는 강력한 인프라를 강조했습니다.
그는 제미나이가 구글 검색을 통해 제공하는 AI 개요 사용자가 15억명을 넘어섰으며, 이에 만족한 사용자들의 질의량이 10%씩 증가하고 있다고 밝혔습니다. 또한 사용자의 의도와 문맥을 파악하여 관련성 높은 정보를 제공하는 AI 모드의 검색 시스템으로 진화할 것을 예고하였는데요. 이는 작년 12월 구글이 등록한 ‘테마 검색 엔진’ 특허와 맥락이 연결됩니다. 앞으로 AI가 장착된 검색은 어떻게 진화할까요?
1. 검색을 확장하는 구글 AI 모드와 쿼리 팬아웃
구글 검색의 AI 모드는 사용자의 질문을 의도에 맞게 확장합니다. 기존의 키워드 중심의 검색과 달리 사용자의 의도를 깊이 이해해 맥락과 연관된 하위 주제를 탐색한다는 점에서 검색이 차별화되고 있습니다.
예를 들어, ‘아이폰 방전’을 검색하면 단순히 배터리 관련 정보만 보여주는 것이 아니라 아이폰 수리, 신규 배터리 성능, 배터리 교체 비용 등 여러 하위 주제를 동시에 탐색해 제시합니다. 마치 부채를 펼치듯 모호한 질문 속에 숨어 있는 여러 주제를 찾아내는 셈입니다. 이러한 방식을 가능하게 하는 핵심 기술이 바로 구글의 쿼리 팬아웃(query fan-out)입니다.
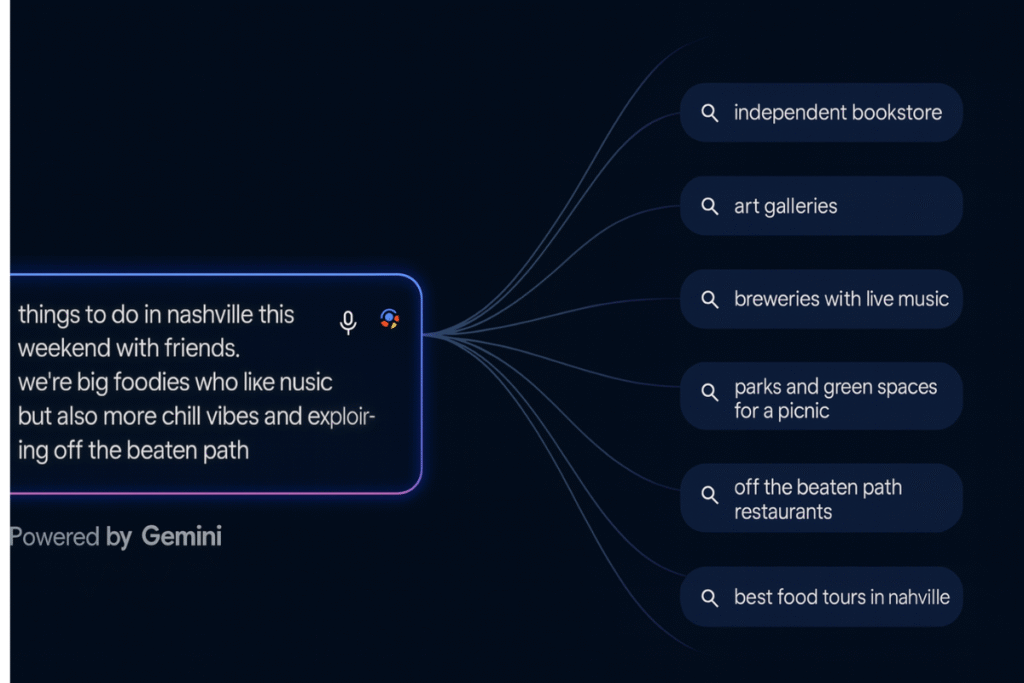
구글은 사용자를 대신해 수많은 쿼리를 동시에 실행하며, 덕분에 사용자는 검색어를 반복 입력하지 않고도 질문과 연관성이 높은(hyper-relevant) 콘텐츠를 빠르게 확인할 수 있습니다.
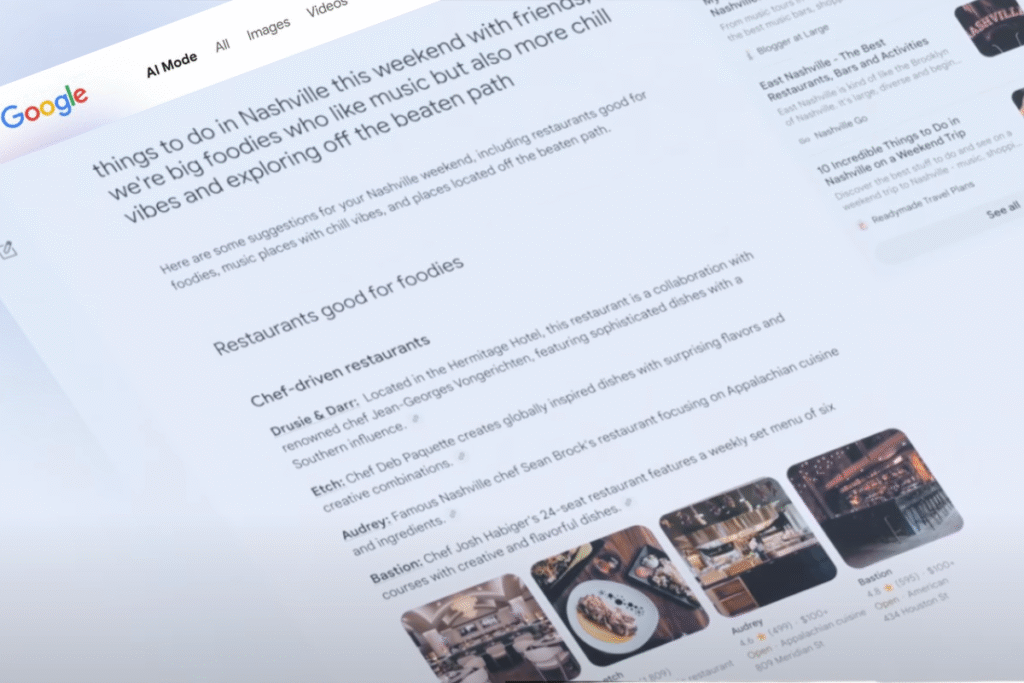
결국 구글 AI 모드는 단순한 검색 기능 확장을 넘어, 검색의 본질적인 변화를 의미합니다. 그렇다면 이러한 변화는 마케팅 관점에서 어떤 의미를 가질까요?
2. 마케팅 패러다임 변화: 구글 AI 모드가 던지는 시사점
구글의 AI 모드는 사용자가 입력한 키워드뿐 아니라, 아직 스스로 자각하지 못한 암묵적 질문까지 예측해 정보를 제공합니다. 이는 고객 여정 전반을 가로지르며 선제적으로 정보를 제공하는 방향으로의 전환이며, 브랜드의 콘텐츠 전략에 중요한 시사점을 던집니다.
먼저, 검색 여정의 초기 단계(질문이 아직 구체화되지 않은 시점)에서 사용자를 효과적으로 사로잡을 새로운 기회가 열렸습니다. 앞으로의 콘텐츠는 명확한 질문에만 답하는 데 그치지 않고, 잠재적인 다음 질문과 숨겨진 요구까지 함께 예측하고 해소하도록 설계되어야 합니다.
그렇다면 브랜드는 이러한 ‘다음 질문’과 ‘숨겨진 요구’를 어떻게 예측할 수 있을까요? 구글 AI 엔진의 작동 원리를 살펴보면 핵심은 주제 엔터티(topic entity)와 쿼리 클러스터(query cluster), 이 두 가지 개념에 있습니다.
이제 구글이 어떻게 사용자의 의도를 해석하고, 이를 기반으로 하위 주제를 생성해 검색 범위를 확장하는지 그 메커니즘을 더 깊이 들여다보겠습니다.
3. 구글 AI 검색의 작동 원리: 주제 엔터티와 쿼리 클러스터
구글이 선제적으로 정보를 제공할 수 있는 이유에는 두 가지 핵심 개념이 있습니다. 바로 주제 엔터티(Topic Entity)와 쿼리 클러스터(Query Cluster)입니다.
주제 엔터티는 질문 속에서 가장 중요한 핵심 주제어이자 실제 존재하는 대상을 뜻합니다. 예를 들어 “뉴욕에서 가장 맛있는 김치찌개 집은?” 이라는 질문에서 핵심은 ‘뉴욕’과 ‘김치찌개’이며, 이들이 검색의 출발점이 됩니다.
쿼리 클러스터는 주제 엔터티에서 파생되는 연관 질문들의 묶음입니다. 예컨대 ‘김치찌개’라는 주제에서 ‘돼지고기 김치찌개 맛집’, ‘김치찌개와 어울리는 메뉴’ 같은 세부 질문들이 생기는데, 이 묶음이 바로 쿼리 클러스터입니다.
구글은 먼저 핵심 주제어를 찾은뒤 그로부터 뻗어 나오는 다양한 질문을 함께 탐색합니다. 덕분에 사용자는 단일 키워드를 넘어서 더 풍부하고 맥락적인 답변을 얻을 수 있습니다. 이제 이 두 가지 개념을 바탕으로, 구글 AI 모드가 어떻게 검색 범위를 확장하는지 단계별로 살펴보겠습니다.
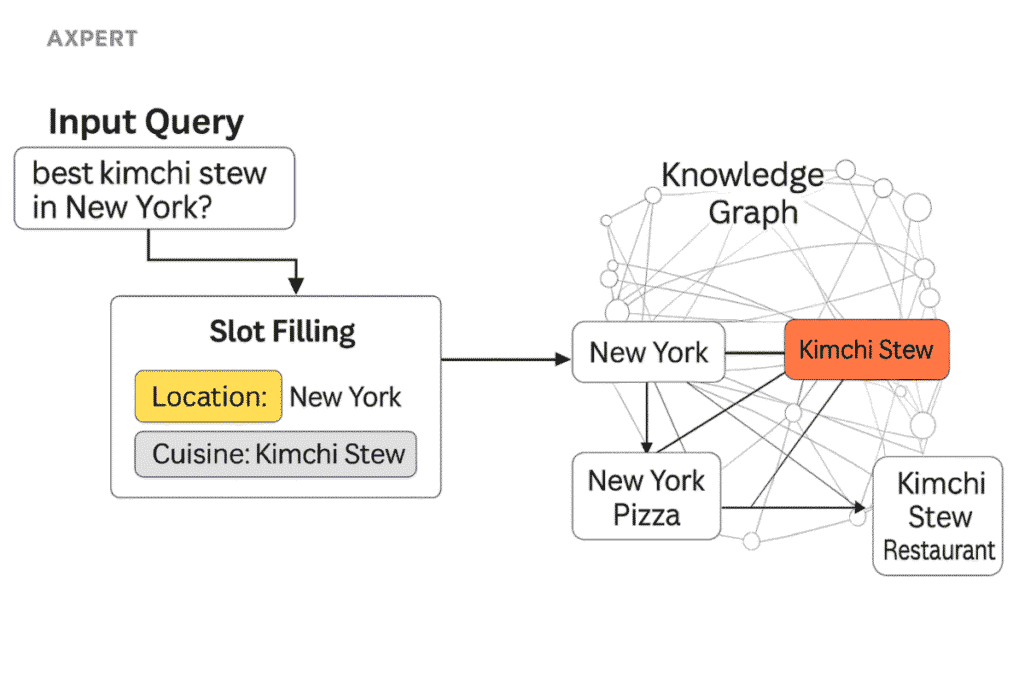
3-1. 사용자의 의도 파악: 쿼리 토큰화와 슬롯화
검색 과정은 사용자의 질문 의도를 이해하는 것에서 출발합니다. 이를 위해 구글은 질문을 가장 작은 의미 단위로 나누는데, 이 과정을 쿼리 토큰화(query tokenization)라고 합니다.
예를 들어 “뉴욕에서 가장 맛있는 김치찌개 집은?”이라는 질문은 다음과 나눌 수 있습니다.
- [뉴욕]: 장소
- [가장 맛있는]: 조건
- [김치찌개]: 대상(entity)
- [집]: 맥락상 ‘식당’
문장을 이렇게 나누는 이유는 바로 의도를 도출하기 위해서입니다. 모든 의도에는 달성을 위해 필요한 핵심 속성이 있으며, 이 속성들의 관계를 조합해야 최종 의도를 정확히 파악할 수 있습니다.
- 장소 + 음식 종류 + 식당 유형 → 음식점 추천
- 출발지 + 도착지 + 출발 날짜 + 도착 날짜 + 인원 → 비행기 예약
즉, 토큰화와 슬롯화는 질문 속에서 속성을 추출하고 이를 구조화하여 사용자의 최종 의도를 드러내는 과정입니다. 앞선 예시의 경우 {장소: 뉴욕, 음식 종류: 김치찌개, 조건: 가장 맛있는}이라는 슬롯이 도출되며, 이를 종합하면 최종 의도는 “음식점 추천”이 됩니다.
3-2. 핵심 주제어 식별: 지식 그래프와의 매칭 (검색 범위 확장의 출발점)
의도를 도출한 뒤, 구글은 질문 속에서 중심이 되는 주제 엔터티를 식별합니다. 앞선 예시에서 ‘뉴욕’과 ‘김치찌개’가 여기에 해당합니다.
구글은 이 주제 엔터티들을 지식 그래프와 연결합니다. 지식 그래프는 세상의 모든 개체와 그 관계를 노드(node)와 엣지(edge)로 이어놓은 거대한 네트워크입니다. ‘뉴욕’과 ‘김치찌개’는 이 네트워크에서 출발점이 되어, 수많은 다른 엔터티 및 관계로 확장할 수 있는 기반이 됩니다.
3-3. 검색 범위의 확장: 쿼리 클러스터 생성과 쿼리 팬아웃
이제 구글은 단순히 “뉴욕의 김치찌개 맛집”만 보여주는데 그치지 않고, 지식 그래프 속 다양한 관계를 활용해 연관된 하위 주제를 자동으로 탐색합니다. 그리고 이를 쿼리 클러스터로 묶어내는데, 이 과정이 바로 쿼리 팬아웃(Query Fan-out)입니다.
- 김치찌개 엔터티
‘김치찌개’는 지식 그래프에서 ‘돼지고기 김치찌개’, ‘참치 김치찌개’, ‘묵은지 김치찌개’와 같은 하위 엔터티들과 “~의 한 종류(is a type of)” 관계를 맺고 있습니다. 이를 통해 구글은 ‘김치찌개’ 클러스터 안에서 다양한 세부 질문을 자동으로 생성합니다. - 뉴욕 엔터티
‘뉴욕’은 ‘뉴욕 피자’와 “~로 유명함(is known for)” 관계를 가집니다. 이를 통해 구글은 “뉴욕을 대표하는 음식”이라는 새로운 클러스터까지 확장할 수 있습니다.
지식 그래프는 핵심 주제에서 출발해 음식의 종류, 위치, 가격, 연관 메뉴 등 사용자가 궁금해할 만한 모든 하위 주제를 자동으로 찾아냅니다. 이 과정을 통해 구글은 사용자의 모호한 질문 속에 숨어 있는 다양한 의도를 포착하고, 검색 범위를 확장합니다. 그 결과 사용자는 자신이 직접 검색어를 확장하지 않아도 연관성이 높은 정보를 얻게 됩니다.
마치며: 의도 해석과 확장의 시대로
오늘 살펴본 AI 모드와 쿼리 팬아웃은 구글 검색이 단순히 키워드 일치에 머무르지 않고, 사용자의 의도와 맥락을 깊이 이해해 하위 주제를 생성하는 과정을 보여줍니다. 이는 검색의 패러다임이 ‘키워드 매칭’에서 ‘의도 해석과 확장’으로 이동하고 있음을 잘 보여줍니다.
마케터에게 이 변화는 단순히 개별 키워드 최적화를 넘어서는 전략을 요구합니다. 이제는 주제 엔터티와 쿼리 클러스터를 기반으로, 사용자의 숨겨진 질문과 다음 질문까지 선제적으로 답할 수 있는 포괄적이고 연결된 콘텐츠가 필요합니다. 이렇게 해야 검색 여정의 초반부터 브랜드를 노출시키고, 궁극적으로 더 강력한 존재감을 확보할 수 있습니다.
다음 글 예고: MUVERA 알고리즘과 전략적 선택
이번 글에서 다룬 것은 구글 검색 과정의 전반부였습니다. 이어지는 과정에서 구글은 신규 알고리즘 MUVERA(Making Multi-Vector Retrieval as fast as Single-Vector Search)을 통해 생성된 후보군을 정교하게 평가하고, 최종적으로 어떤 정보를 어떤 순서로 보여줄지를 결정합니다.
다음 글에서는 MUVERA가 ‘관련성’과 ‘신뢰성’을 어떻게 수치화하고, 그 결과가 실제 검색 결과 배열에 어떤 영향을 미치는지를 분석하겠습니다. 이를 통해 마케터가 실질적으로 어떤 전략적 선택을 해야 하는지도 함께 짚어보겠습니다.




