


구글은 키워드 중심 검색의 한계를 넘어, 더 확장된 검색 경험을 제공하기 위해 패러다임을 전환하고 있습니다. 2024년, 구글은 스탠퍼드 연구진과 공동으로 MUVERA(Multi-Vector Retrieval via Fixed Dimensional Encodings) 알고리즘을 개발하였으며, 이는 현 구글 검색 시스템에 도입되고 있습니다. MUVERA는 사용자의 의도를 더 정확하게 반영하면서도, 이전보다 더 빠른 속도를 동시에 구현합니다.
이러한 변화는 곧 콘텐츠 평가 방식의 변화를 의미합니다. . AI 기반 검색 환경에서 우리 콘텐츠를 노출시키려면, MUVERA의 작동 원리를 제대로 이해하는 것이 필수입니다. 지금부터 MUVERA가 왜 필요했고, 어떻게 동작하며, 콘텐츠 전략에 어떤 의미가 있는지 깊이 들여다보겠습니다.
1. 검색 패러다임의 변화: 키워드에서 벡터 기반 검색으로
검색의 패러다임이 키워드 기반에서 맥락 기반의 벡터 검색으로 전환되고 있습니다.
전통적인 키워드 검색은 쿼리의 단어가 문서와 문자적으로 얼마나 일치하는지를 평가합니다. TF-IDF, BM25와 같은 알고리즘은 단어의 빈도에 의존하기 때문에, ‘집’과 ‘하우스’처럼 의미는 같지만 단어가 다른 경우를 처리하지 못하는 어휘적 간극 문제를 극복하지 못했습니다.
이 한계를 해결하기 위해 벡터 기반 검색이 등장했습니다. 텍스트를 다차원 공간의 좌표(벡터)로 변환하면, 단순한 단어 일치가 아닌 의미적 유사성을 기반으로 검색 결과를 제공할 수 있습니다. 예를 들어, ‘학교’ 벡터는 ‘초등’, ‘학생’, ‘교사’ 벡터와 가까운 위치에 자리하여, 사용자 의도를 더 정확하게 파악할 수 있게 됩니다.
2. 벡터 검색의 난제와 MUVERA의 해법
1-2. 문맥적 정확도 vs 검색 속도의 딜레마
벡터 검색은 맥락적으로 훨씬 더 정교한 결과를 보여주지만, 속도 문제에 봉착했습니다. 정확도를 높이려면 쿼리와 문서를 작은 단위로 잘라 각각 여러 개의 멀티 벡터 집합으로 변환하고 연산해야 하는데, 여기서 연산량이 기하급수적으로 폭발합니다.
예를 들어, 쿼리가 10개의 벡터 집합이고 문서가 1,000개의 벡터 집합으로 표현된다면, 총 10 × 1,000 = 10,000번의 유사도 계산이 필요합니다. 이 과정이 쌓이다 보면, 쿼리 하나에 대한 결과를 받기까지 무려 10분 가까이 걸리는 일이 발생합니다.
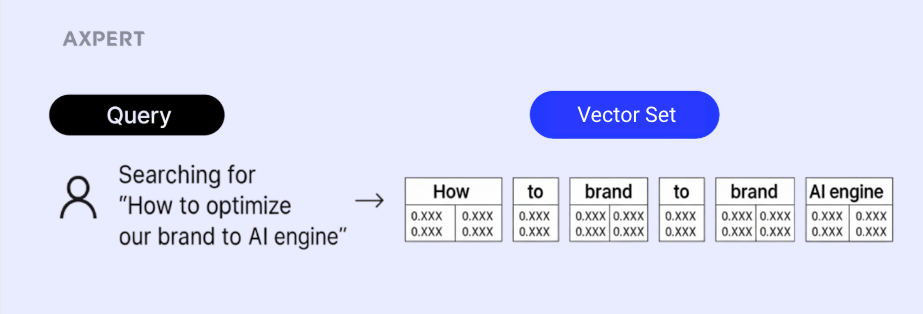
이 문제의 근본적인 원인은 멀티 벡터 구조에 MIPS 인덱스 적용하기 어렵다는 데 있습니다. MIPS(Maximum Inner Product Search)는 대규모 검색 시스템에서 단일 벡터를 기반으로 후보군을 초고속으로 추려내는 핵심 기법입니다.
이를 피하려고 문서를 강제로 단일벡터로 압축하면 검색은 빨라지지만 정확도는 크게 떨어집니다. 바로 이 정확도와 속도의 딜레마를 풀기 위해 MUVERA 알고리즘이 등장했습니다.
2-2. MUVERA: 속도와 정확도 모두 해결
구글은 멀티 벡터 연산의 정확도를 놓치지 않으면서도, 동시에 속도를 높일 방법을 찾았습니다. 바로 고정 차원 인코딩을 통한 다중 벡터 검색, MUVERA입니다.
MUVERA는 중요한 정보를 보존한 채 쿼리와 문서를 하나의 단일 벡터로 변환하는 방식을 도입했습니다. 실제 검증 과정에서 이 단일 FDE 벡터와 원본 벡터 집합 간의 유사도 차이가 거의 거의 0(ϵ, 입실론)에 수렴함이 확인되었습니다. 즉, 의미 손실 없이 단일 벡터로 표현하는 데 성공한 것입니다.
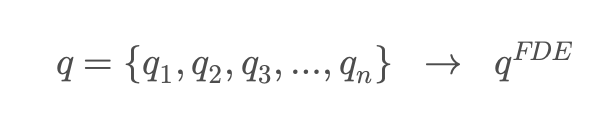
이 덕분에 MUVERA는 기존에 단일 벡터 연산에서만 가능했던 MIPS 인덱스 기반의 초고속 검색을 활용하는 동시에, 높은 정확도까지 확보했습니다. MUVERA는 시맨틱 검색의 최대 난제였던 “정확도 vs. 속도”의 딜레마를 해결한 혁신적인 알고리즘입니다.
3. MUVERA는 어떻게 동작할까?
MUVERA는 사용자의 쿼리와 가장 관련성 높은 문서를 빠르고 정확하게 찾아내기 위해 다음과 같이 동작합니다.
3-1. FDE 생성: 4단계 압축을 통한 단일벡터화
FDE(Fixed Dimensional Encoding)는 다중 벡터 집합을 하나의 단일 벡터로 변환하는 과정입니다. 문서는 검색 전에 미리 변환되고, 쿼리는 입력 시 즉시 변환되어 실시간 검색의 연산 부담을 크게 줄입니다.
1. 원본 멀티 벡터 집합 생성
하나의 문서는 제목, 핵심 단락, 결론 등 여러 의미 단위로 구성되며, 각 단위는 고유한 **특징 벡터(p1,p2,…)**로 변환됩니다. 이렇게 얻어진 벡터들의 묶음을 다중 벡터 집합 (P)이라 부르며, 이는 문서의 세밀한 의미적 지문 역할을 합니다.
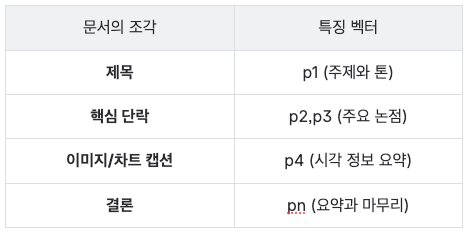
2. 공간 분할 및 대표 벡터 선정
문서나 쿼리를 벡터로 변환하면, 단어와 의미 단위들이 고차원 임베딩 공간 속에 점처럼 흩어져 있습니다. 이때 비슷한 의미를 가진 벡터들은 서로 가까이 모여 있습니다.
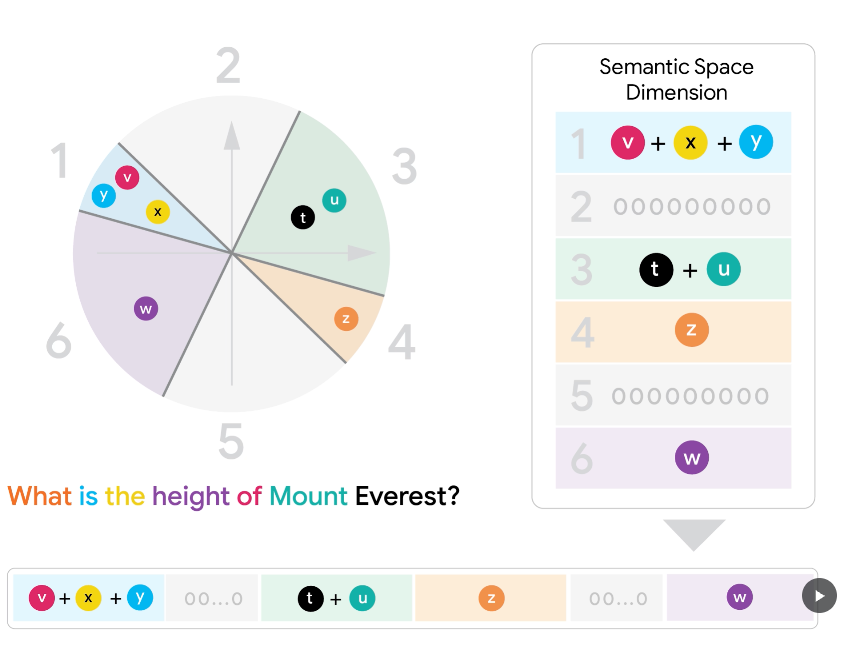
하지만 수많은 벡터를 그대로 계산하면 연산량이 폭발적으로 늘어나기 때문에, MUVERA는 LSH(Locality-Sensitive Hashing) 기법을 사용해 공간을 64개의 영역으로 나눕니다.
예를 들어, What is the height of Mount Everest? 쿼리는 다음과 같이 분할 됩니다.
is, the, of 같은 기능어들은 같은 영역에 배치
Mount, Everest는 지명 개념으로 또 다른 영역
height는 별도의 의미 축에 따라 다른 영역
What도 축약 표현으로 또 다른 영역
즉, 비슷한 의미끼리 같은 공간에 묶이도록 하는 과정입니다. 만약 어떤 영역에 단어가 전혀 들어오지 않으면, 해당 공간은 0이나 대체 벡터로 채워집니다.
이후 각 영역에서 대표 벡터 하나를 뽑습니다.
쿼리의 경우 → 합산값(Sum)
문서의 경우 → 평균값(Mean)
그 결과, 쿼리 또는 문서는 64개의 대표 벡터를 가지게 됩니다.
3. FDE 생성
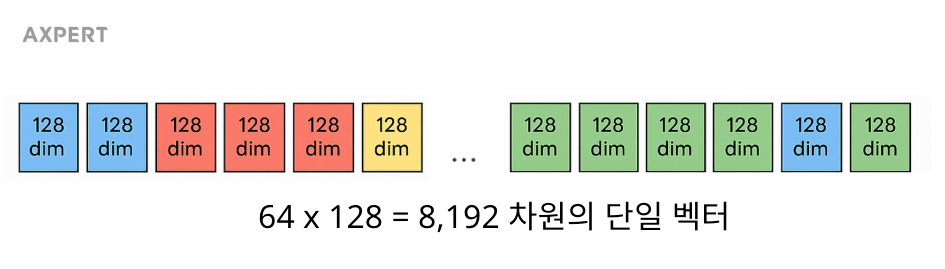
앞 단계에서 뽑은 64개의 대표 벡터를 차례대로 이어 붙이면 하나의 단일 벡터가 완성됩니다. 각 벡터는 128차원이므로, 총 64개를 합치면 8,192차원 벡터가 되고, 이는 문서의 의미를 압축해 담은 문서 지문(pFDE) 역할을 합니다.
4. 양자화를 통한 FDE 벡터 압축
하지만 문제가 있습니다. 차원이 너무 크다 보니, 메모리와 연산 비용이 지나치게 커져 수억 개 문서를 동시에 처리하기 어렵다는 점입니다.
이를 해결하기 위해 MUVERA는 Product Quantization(PQ) 기법을 적용합니다.
8차원씩 벡터를 쪼갠 뒤,
각 조각을 미리 정의된 256개의 기준값과 비교해 가장 가까운 코드로 치환합니다.

즉, 긴 벡터를 그대로 저장하는 대신 짧은 번호(코드)로 바꾸는 것이죠. 이 방식 덕분에 벡터 크기는 32배 이상 압축되며, 놀랍게도 정확도 손실은 1% 미만에 불과합니다.
결국 MUVERA는 메모리를 최소로 쓰면서도, 실시간 검색에 필요한 속도와 정밀도를 모두 잡을 수 있게 됩니다.
3-2. MIPS 인덱스로 최적 후보군 선별
FDE로 단일 벡터화가 끝나면, 이제 수억 개 문서 중 연관성이 높은 후보면 추려내야합니다. 여기서 쓰는 것이 MIPS(Maximum Inner Product Search) 인덱스입니다.
모든 문서 벡터 p_{FDE}는 MIPS 인덱스에 저장됩니다. 이 인덱스는 마치 도서관에서 책의 주제별 색인표와 같은 역할을 합니다. 이는 마치 도서관에서 책을 찾을 때 모든 책을 읽지 않고 관련 서가 구역부터 찾는 방식과 유사합니다.
덕분에 검색 속도는 압도적으로 빨라집니다.
MIPS 검색 과정은 다음과 같습니다:
쿼리 입력: “고전 역학에서 뉴턴의 법칙 관련 자료”
인덱스 탐색:인덱스는 쿼리와 관련 있을 가능성이 높은 구역, ‘과학 → 물리학 → 고전 역학’ 구역으로 곧바로 이동
후보군 선별:
쿼리 벡터 qFDE와 문서 벡터 pFDE 간의 내적(Inner Product) 값을 계산합니다.
그 결과 가장 유사도가 높은 상위 k개의 문서만 후보군으로 추려냅니다.
3-3. Chamfer 유사도로 최종 순위 매기기
후보군이 모였으면, 이제 정밀 검증입니다. MUVERA는 Chamfer Similarity로 쿼리와 문서를 양방향으로 비교해 최종 순위를 결정합니다.
완전성: 쿼리의 모든 요소가 문서에서 대응점을 찾는가?
연관성: 문서의 핵심 요소가 쿼리와 실제로 연결되는가?
Chamfer 유사도 예시:
쿼리: “고전 역학에서 뉴턴의 제3법칙” → 쿼리 벡터 집합 Q = {q₁(고전), q₂(역학), q₃(뉴턴), q₄(제3법칙)}
문서: “뉴턴의 제2법칙과 고전 역학 기초” → 문서 벡터 집합 P = {p₁(뉴턴), p₂(제2법칙), p₃(고전), p₄(역학)}
Q → P 방향: 제3법칙은 문서에 없음 → 감점 (완전성 떨어짐)
P → Q 방향: 문서의 제2법칙은 쿼리에 없음 → 감점 (연관성 떨어짐)
따라서 “부분적으로 유사하나, 완전 일치 아님”으로 평가되어 최종 순위는 낮아집니다.
Chamfer는 단순 단어 겹침이 아니라, 쿼리 의미를 빠짐없이 커버하면서(완전성) 불필요한 잡음을 줄인(연관성) 문서를 우선합니다.
4. MUVERA 원리를 콘텐츠 전략에 적용하기
지금까지 MUVERA의 검색 원리를 살펴봤습니다. 그렇다면 실제 콘텐츠를 작성할 때, 쿼리에 적합한 문서로 채택되려면 어떤 전략이 필요할까요?
MUVERA는 수많은 문서 중 후보군을 추려낸 뒤, 정밀하게 평가하여 노출 여부를 결정합니다. 따라서 각 단계별로 선택받기 위한 콘텐츠 전략을 이해하는 것이 중요합니다.
4-1. FDE 관점: 필터링에서 살아남는 콘텐츠 작성법
먼저 MIPS 인덱스 기반 필터링을 통과해야 합니다. 검색의 성패는 결국 쿼리 FDE와 문서 FDE 사이의 내적 점수에 달려 있습니다.
문서 P는 제목, 소제목, 본문, 이미지, 결론 등 다양한 의미 단위의 벡터 합으로 표현됩니다. 따라서 예상되는 쿼리와 맞닿는 핵심 내용을 반드시 포함해야 합니다.

또한 문서 FDE는 벡터들의 평균으로 압축되기 때문에, 불필요한 잡음(노이즈)이 섞이면 그것마저 하나의 대표 벡터로 반영됩니다. 이 경우 쿼리와의 내적 점수가 낮아져 초기에 걸러질 수 있습니다.
4-2. Chamfer 관점: 최종 랭킹을 높이는 정보 배치 전략
필터링을 통과한 뒤에는 완전성과 연관성이 최종 순위를 좌우합니다.
이를 위해서는 쿼리 벡터(qᵢ)가 다양한 문서 벡터(pⱼ)와 매칭될 수 있도록 의미적 다양성을 확보해야 합니다. 같은 단어만 반복하지 말고, 동의어나 맥락적 표현을 활용해 쿼리의 의도를 풍부하게 담아야 합니다.
또한 문서 벡터(pⱼ)는 핵심 내용을 충실히 포함해야 합니다. 쿼리(qᵢ)와 대응될 수 있도록 주제를 깊이 있게 다루되, 불필요한 정보는 과감히 배제해야 합니다. 과잉 정보는 오히려 잡음이 되어 순위를 떨어뜨릴 수 있습니다.
마치며: MUVERA 이해가 곧 콘텐츠 전략이다
MUVERA 원리를 이해해야 하는 이유는 분명합니다. 우리의 콘텐츠가 어떻게 선택되고, 왜 배제되는지를 결정하는 기준이 바로 여기에 있기 때문입니다.
결국 좋은 콘텐츠란, 사용자의 질문을 빠짐없이 커버하면서도 불필요한 잡음을 철저히 제거한 콘텐츠입니다. MUVERA는 그런 문서를 ‘의도에 맞는 콘텐츠’로 인식하고, 상위에 노출시킵니다.
이번 글에서는 MUVERA의 동작 원리을 기반으로 한 핵심 전략을 살펴보았습니다. 다음 글에서는 이 원리를 실제 콘텐츠 제작에 구체적으로 적용할 방법론을 다루겠습니다.




